
Syntéza bílkovin (proteosyntéza) je složitý proces, který se v mnohém odlišuje od syntézy sacharidů a lipidů. Hlavní rozdíl je v tom, že informace o stavbě proteinů lidského těla jsou v buňce uloženy v jádru ve struktuře DNA a do struktury proteinu se tato informace musí „přepsat“ a „přeložit“.
Co je základem proteinu? Je to určitá sekvence aminokyselin, z nichž se protein skládá. Těchto aminokyselin tvořících proteiny v lidském těle rozlišujeme celkem 20. Informace o pořadí sekvence aminokyselin daného proteinu je schována uvnitř molekuly DNA. DNA (deoxyribonukleová kyselina) je tvořena dvěma řetězci tvořenými vzájemně propojenými nukleotidy. Nukleotid je složen z nukleové báze, sacharidu a fosfátu. Nukleová báze (adenin - A, guanin - G, cytosin - C, thymin - T) je napojena na molekulu sacharidu (v tomto případě deoxyribóza) a molekuly těchto sacharidů jsou vzájemně propojeny molekulami fosfátů za vzniku dlouhého řetězce. Řetězce jsou dva. Podle pravidla komplementarity jsou nukleotidy umístěny, tak že proti sobě mohou být jen určité báze. Proti adeninu může být thymin (A-T) a proti cytosinu může být guanin (C-G)*. Tyto komplementární báze jsou vzájemně stabilizovány pomocí slabých vodíkových vazeb. Dvě vazby jsou mezi A-T a tři vazby jsou mezi C-G.
* Stejné pravidlo platí pro RNA, kde je ovšem místo molekul thyminu vždy přítomen uracil. Takže pro RNA platí A-U a C-G (molekuly RNA sice netvoří dvoušroubovici, ale přesto se v určitých situacích řetězce RNA do těsného kontaktu dostávají).
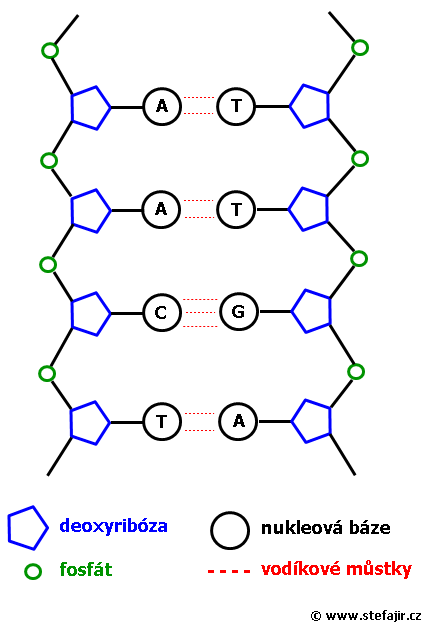
Schéma - krátký úsek DNA, vidíme dva řetězce složené z nukleotidů, nukleové báze jsou propojené slabými vodíkovými vazbami
Transkripce
Záměrně transkripci popisuji až trestuhodně zjednodušeně. Transkripce znamená „přepis“ a probíhá v jádře buňky. Když přijde signál, že má být určitý protein vytvořen, oddálí se od sebe díky enzymu RNA polymeráza v určitém místě oba řetězce DNA. Jeden z řetězců je tzv. kódující a druhý nekódující. K nekódujícímu řetězci se následně opět činností enzymu RNA polymeráza vytvoří řetězec mRNA, který má logicky stejné pořadí nukleotidů jako kódující řetězec (kromě toho, že místo každého thyminu má uracil). Vše je dobře vymyšlené, v určitém místě řetězce DNA určité pořadí nukleotidů činnost RNA polymerázy ukončí. Následují tzv. posttranskripční úpravy během kterých se vzniklá molekula mRNA dále upravuje (jsou upraveny konce a "vystříhány" některé části molekuly).
Konečným výsledkem transkripce je definitivní mRNA (messenger RNA), jejíž pořadí nukleotidů je stejné jako u kódujícího řetězce DNA s tím rozdílem, že místo thyminu je v ní přítomen uracil (thymin se vyskytuje pouze v DNA a uracil pouze v RNA).
![]()
Schéma transkripce - molekula mRNA vzniká podle nekódujícího vlákna DNA
Translace
Messenger znamená "posel" a přesně to je role mRNA. Její molekuly se dostávají na ribozómy, kde se informace nesená mRNA musí "přeložit" do pořadí aminokyselin v řetězci vznikajícího proteinu. Trojice nukleotidů mRNA kóduje jednu aminokyselinu (tzv. kodon). Molekula aminokyseliny je přinesena k mRNA pomocí malé molekuly tRNA (transferová RNA). Pak se tRNA díky trojici nukleotidů přítomných v jedné její části (tzv. antikodon) napojí na mRNA řetězec tak, že zmíněné tři nukleotidy na mRNA a tRNA (tj. kodon a antikodon) sobě vzájemně odpovídají (adenin-uracil, guanin-cytosin). Translace obvykle začíná start kodonem AUG, který zároveň kóduje aminokyselinu methionin. Kromě toho existují stop kodony, které stran aminokyseliny nadávají smysl a translaci zastaví. Molekuly aminokyselin se následně spojí a řetězec proteinu je hotový.
![]()
Schéma translace, tRNA přináší aminokyseliny k mRNA a řadí se podle vzájemně odpovídajících kodonů a antikodonů
Pozn.: Kromě stop kodonů platí, že jeden kodon kóduje pouze jednu určitou aminokyselinu, na druhou stranu jedna aminokyselina může být kódována jedním nebo více kodony. Například již zmíněný methionin je určen kodonem AUG (tj. pořadí adenin-uracil-guanin), ale prolin je určen kodony CCU, CCC, CCA a CCG. To znamená, že k pořadí AUG mRNA se přiloží tRNA nesoucí methionin. Molekuly tRNA nesoucí prolin se mohou přiložit k mRNA v místech, kde jsou přítomny kodony CCU, CCC, CCA a CCG.
Z toho logicky plyne, že i určitá molekula tRNA s konkrétním antikodonem může nést pouze jednu konkrétní aminokyselinu, ale konkrétní aminokyselina může být nesena jednou nebo více molekulami tRNA. Například zmíněný methionin může být nesen pouze tRNA s antikodonem UAC (odpovídá kodonu AUG), zatímco třeba zmíněný prolin může být nesen tRNA s antikodonem GGA, GGG, GGU a GGC.
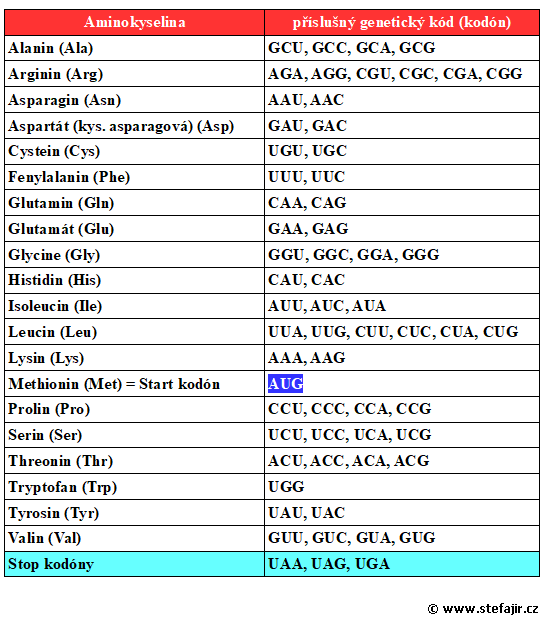
Schéma - aminokyseliny a jejich kodony v mRNA včetně start kodonu a stop kodonů
Prostorová tvorba vlastního proteinu a další posttranslační modifikace
Vytvoření určitého pořadí aminokyselin a jejich propojení sice protein definuje, ale k jeho správné funkci musí být přítomna i správná trojrozměrná struktura. Proteiny nemají podobu rovných aminokyselinových řetězců, ale mívají dosti složitou 3D strukturu a mohou obsahovat i jiné molekuly než aminokyseliny. Proto probíhají další složité úpravy, na jejichž konci by měla být funkční prostorově uspořádaná molekula proteinu. Proces může zahrnovat i úpravy, jako je "odstřižení" částí vzniklého řetězce, napojování dalších jednoduchých nebo složitých molekul na vzniklý protein nebo vznik chemických vazeb mezi nesousedními částmi řetězce aminokyselin (které se musí prostorově přiblížit).


